

Which Claude model should you use? Effort settings, thinking mode, and Fable 5 drama
When to use which model, what the effort settings do, and why the most powerful one lasted only 3 days


TL;DR: For routine work, use a fast model with thinking off. For writing, analysis, or strategy, use Claude Opus 4.8 with thinking on at Medium or High effort. Save Max effort (and, when available, the heaviest models) for genuinely hard, high-stakes problems. Ignore the rumour that Opus 4.6 beats 4.8, it doesn’t. And “effort” is a dial that nudges how hard the model works, not a fixed compute budget.
Note: At the time of publishing, Claude Fable 5 is suspended. This piece reflects the situation on June 16, 2026.
A few years ago, choosing an AI model was down to whatever was available. So you typed a sentence into a clean white text box, hit enter, and words appeared. Now the hard part isn’t writing a prompt, it’s deciding which Claude model and effort setting to use before you start.
Opening a frontier AI interface today feels like walking into the cockpit of a commercial airliner. You’re confronted with a dizzying array of model drop-downs, “Thinking” toggles, and “Effort” settings ranging from Low to Max.
A week or two ago (before Fable), a Human+AI reader named Steve sent in a question that captures the collective confusion of everyone trying to keep up with AI models:
“Can you explain when to use various models? I heard today that I should be using Claude Opus 4.6 and ignore Opus 4.8. Then there are these effort selections: low, medium, high, Max. And finally there is a toggle for ‘thinking.’ Like what model and effort do I choose for which task? What do those choices actually do to the model?”
Steve, you’ve pinpointed the friction point of modern AI. And your timing is uncanny: as you wrote, the most powerful switch on the dashboard was being installed. Then, 3 days later, the US government flipped it back off. (More on that in a bit.)
Let’s look at these settings, debunk the rumour you heard, and give you a framework to configure your workspace without blowing through your budget or your time.
Debunking the myth: Opus 4.6 vs. Opus 4.8
First, let’s clear up that rumour about ignoring the newer Claude Opus 4.8 in favour of version 4.6.
The rumour stems from an architectural change. On Opus 4.6, you could manually set a hard “thinking token budget” (telling the machine how many tokens to spend on reasoning). That created two failure modes: cap it too low and the model truncated useful reasoning; cap it too high and it burned thousands of tokens overthinking a “hello.”
When Opus 4.8 shipped on May 28, Anthropic removed the knob entirely. Try to set a fixed thinking budget now and you get a 400 error. The model uses adaptive thinking instead: it evaluates the complexity of each request and decides internally how much to reason. Some power users read that loss of manual control as a downgrade. It isn’t, it’s a quality-of-life upgrade that ends the budget-guessing game.
Stick with the latest version. You may have seen a stat claiming 4.8 is “4x less likely” to let logic errors slip. I haven’t been able to confirm that number, so I’d treat it as folklore until Anthropic publishes it.
What the thinking toggle and effort settings do
When you move these controls, you’re changing how the model spends its reasoning. But not in the literal, mechanical way the interface implies. This is where most people get mixed up.
The thinking toggle: Turning on the scratchpad
Thinking OFF (pattern recognition): The model answers on intuition, predicting the next likely word instantly. Lightning-fast and cheap, but it can’t catch its own logical errors before they hit your screen.
Thinking ON (test-time compute): The model gets a hidden workspace. Before it types a visible word, it outlines its approach, tests assumptions, catches contradictions, and backtracks at dead ends.
The effort setting: A dial, not a budget
If the toggle turns the brain on, the Effort setting influences how hard it works. You’re seeing four options: Low, Medium, High, Max, which is what the consumer app surfaces. The underlying API actually exposes a fifth step, xHigh, tucked between High and Max, and Opus 4.8 defaults to High. The app gives you the simplified dial, and the engine has one extra notch.
The nuance the dashboard hides, and the single most misunderstood thing in AI tooling right now, is: effort is a soft behavioural signal, not a hard token cap. You’re not buying a fixed amount of compute. You’re nudging the model’s disposition toward thoroughness. It will still decide, adaptively, how much reasoning a given prompt warrants. Higher effort tilts it toward “check your work again,” it doesn’t force it to spend a set number of tokens.
The golden rule: Don’t default to “Max” for routine work. Thinking tokens cost the same as output tokens. Ask for a Max-effort summary of a short email chain and you won’t get a better summary, just a bigger bill and a longer wait.
Claude Fable 5: The heavyweight that lasted 3 days
On June 9, Anthropic publicly released Claude Fable 5, its first widely accessible Mythos-class model. It’s the most capable model the company has made generally available. It scores state-of-the-art on nearly every benchmark, has a 1-million-token context window, and is built for long-horizon autonomous work: running multi-stage projects like codebase migrations unattended for hours, writing its own tests and correcting its mistakes. Andrej Karpathy called it “a major-version-bump-deserving step change.”

Then, the catch. To ship something this powerful, Anthropic wrapped it in conservative real-time classifiers. Ask about cybersecurity, biology, chemistry, or frontier AI architecture and Fable freezes, handing your prompt to the safer Opus 4.8. Early users reported the guardrails tripping on legitimate research, one widely shared line called it “less a model launch than a preview of AI inequality.”
The data-retention bombshell. Fable came with a mandatory 30-day data retention policy. Crucially, it overrides existing Zero Data Retention enterprise agreements. Flagged content can be held up to two years. Within days, Microsoft restricted employee access over the concern. For anyone touching source code, legal documents, health records, or M&A material, that’s a genuine compliance problem.
The plug pulled. On June 12, 3 days after launch, the US government issued an export-control directive suspending Fable 5 (and its sibling Mythos 5), citing national security, and barring access for any foreign national inside or outside the country.
So the most powerful tool on your dashboard is, for now, gone. Which is a lesson itself: more switches doesn’t mean more control. The frontier is shaped by forces (safety classifiers, data policy, governments) that sit outside our control. Building your workflow around any single flagship is a bet. And a good reason to have local AI in your back pocket.
Local AI: What it is, why it's trending, and how to install it yourself

TL;DR: A growing number of people are running AI models on their own computers instead of in the cloud. Here’s why, and how to try it yourself.
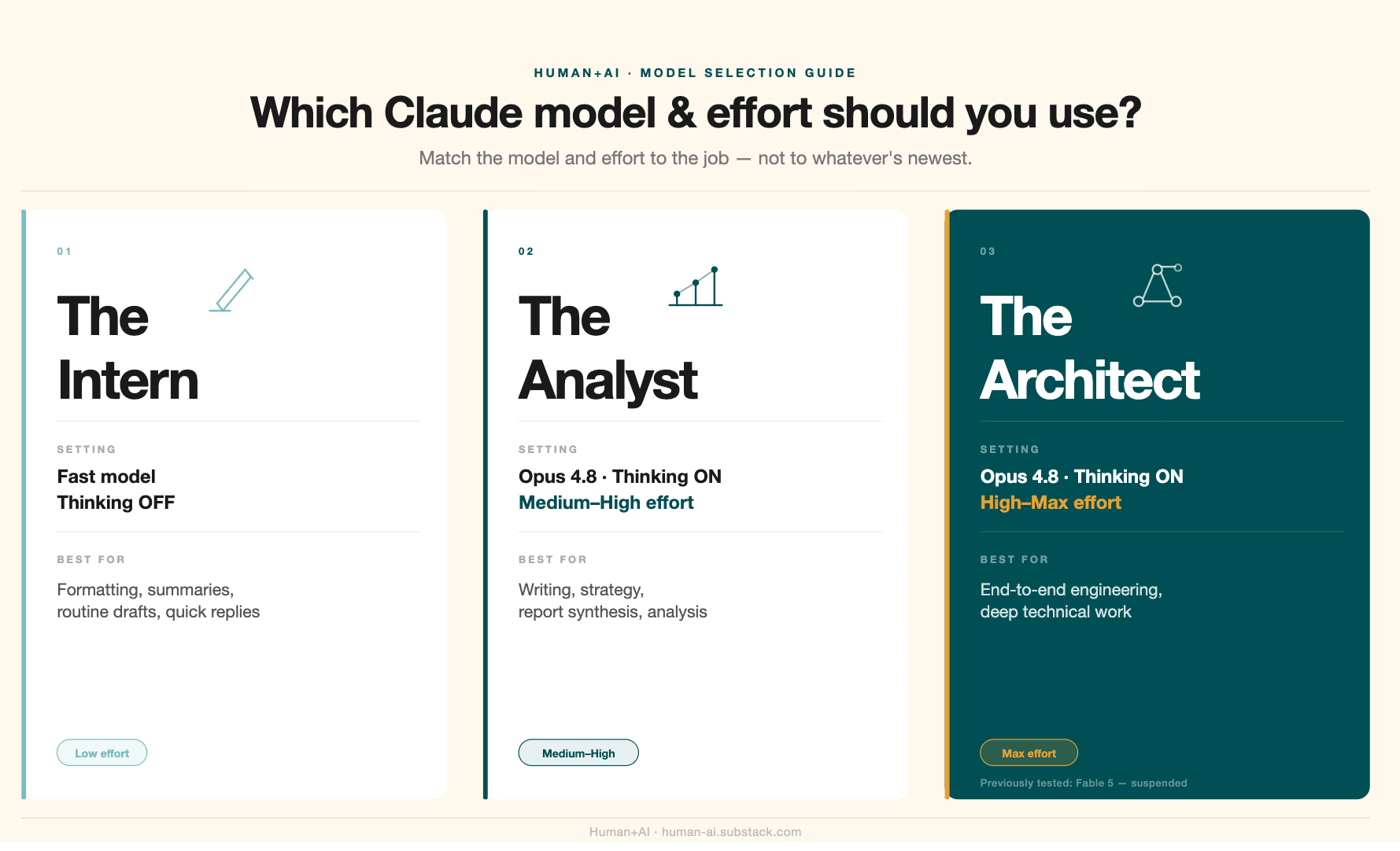
Which Claude model and effort to choose: The daily workspace matrix
Map your choices to the complexity and stakes of the work in front of you — not to whatever’s newest.
The “Intern” Formatting, basic summaries, routine drafts
Fast model, Thinking OFF (or Low effort) gives instant results without burning expensive compute
The “Analyst” Nuanced writing, strategy, report synthesis
Opus 4.8 + Thinking ON, Medium/High effort gives enough reasoning room for natural, well-argued prose
The “Architect” End-to-end engineering, multi-file code, deep technical work
Opus 4.8 at High effort (Max for the gnarliest problems) today (this is the slot Fable 5 was built for — revisit if it returns and clears your data-policy bar)
For high-stakes, hours-long problems where you want self-verification
The takeaway
AI isn’t a single text box, it’s a dynamic toolkit, and an unstable one. Knowing when to dial effort up or down protects your workflow, your wallet, and your time. Use fast models to clear the clutter, Opus 4.8 to do serious thinking, and treat any single “most powerful” model as a tool you’re renting, not a foundation you’re building on. This month proved how quickly things can change.
What about you? Have you started playing with the effort settings — or did you get to try Fable 5 before it went dark? Hit reply or comment on the Substack post and tell me where you’re parking your subscription dollars this month.
Frequently Asked Questions
Is Claude Opus 4.6 better than Opus 4.8? No. The rumour comes from Opus 4.6 letting you set a manual thinking-token budget, which 4.8 removed in favour of adaptive thinking. That’s a usability upgrade, not a downgrade, so use Opus 4.8.
What does the “thinking” toggle do in Claude? With thinking off, the model answers instantly from pattern recognition. With thinking on, it works in a hidden scratchpad first. It outlines, tests assumptions, and catches its own errors before it replies. Turn it on for anything that requires reasoning.
What’s the difference between Low, Medium, High, and Max effort? Effort nudges how hard the model works on a problem. It’s a soft behavioural signal, not a fixed compute budget — higher effort biases the model toward thoroughness, but it still decides adaptively how much reasoning each prompt needs. Default to Medium/High; reserve Max for hard, high-stakes work.
Is Claude Fable 5 still available? As of June 16, 2026, no. Fable 5 launched June 9 and was suspended June 12 under a US government export-control directive. Until that changes, use Opus 4.8 for the heaviest tasks.
AI in the news

New from Compute! Three AI labs filed IPO documents in 40 days. Collective valuation: $2.84 trillion, about two-thirds of India’s GDP. The new issue digs into the five banks underwriting all 3 deals, the valuations that rhyme with Yahoo in 2000, and the times Sam Altman said “we have not decided.”
Today I used Opus on high effort to do deep code spelunking to figure out how something worked across repos, develop an agenda for a meeting from it, then used Sonnet on medium effort to make sure the agenda was legible enough to me to present. It's backwards of how most people use the different models, using a higher-level model to check the lower one's work. I needed it because my level of understanding of the material is lower-fidelity than what Opus produced (correct, deeply researched, but opaquely presented)